Migrating Graylog Servers
This is the first in a multi-part series where I explore the process of transforming an existing Graylog install into a resilient and scalable multi-site installation.
When I started at ${DayJob} we were using a single server Graylog2 for log storage. Honestly it
works out pretty well, the only real resource hog is ElasticSearch which will eat up as much
memory as you can ever throw at it. Occasionally we would notice the Java processes would be
running low on memory so we’d add a few more GB to the VM and walk away. Since that time there
have been several new versions of GL2 released, installation has gotten easier, and most importantly
we now have packages that install to predictable locations. Instead of trying to migrate an existing
system from a source install to package I opted to take the opportunity to fully evaluate the design
of our logging environment.
My team supports a mix of Windows and Linux servers, almost entirely virtualized, and a large number of network devices spread out among a fistful of remote office sites and multiple geographically distributed datacenters. As one might expect certain business units are more heavily supported in one location or another but whenever possible, and when it actually makes sense, we strive for proper site diversity. I definitely wanted to take this into account during my evaluation.
Quite frankly, the the single-server stack still provides sufficient performance so don’t need anything quite so complex as the Bigger Production Setup described in the Architectural Considerations. However we can somewhat easily adapt it to fit our needs. The overall goal of the new design was to achieve something akin to a hot active-active environment with cross-site replication. For performance purposes each site should have their own log collection capabilities, similarly the Graylog2 Servers should store collected logs to a local ElasticSearch data node. In order to tolerate the entire loss of a site each site should be able to operate independently and, more importantly, we shouldn’t have to worry about data loss if a site disappears or the link breaks. To that end we’re going to take a setup that looks something like this
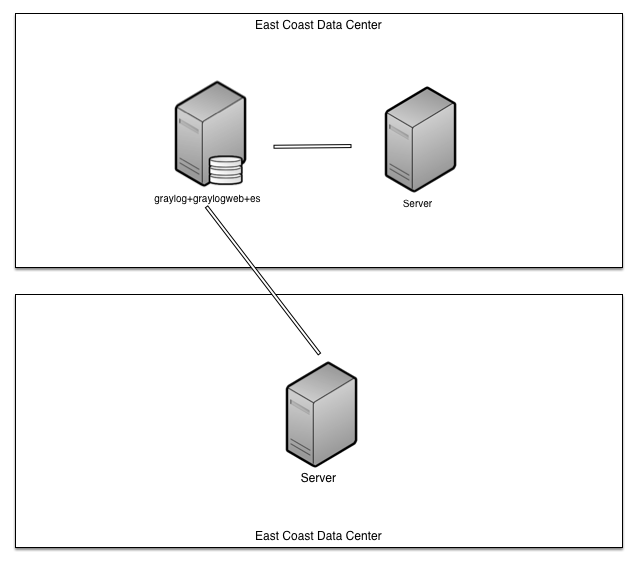
to one that’s more like
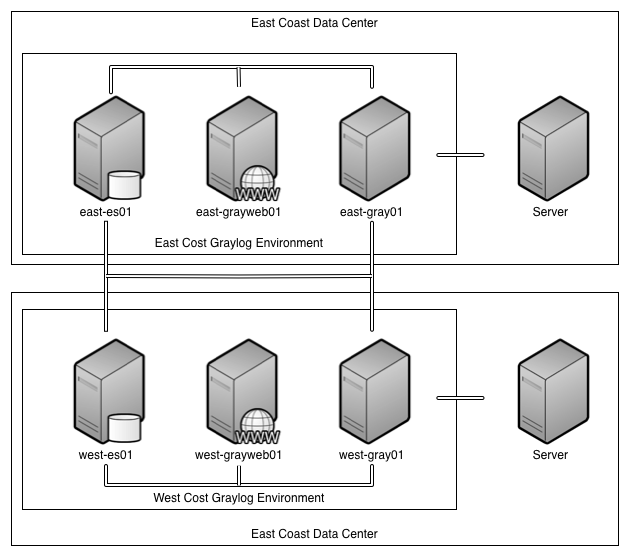
Fortunately the underlying ElasticSearch environment has pretty good support for scaling out additional nodes, as does Graylog2 Server. This will let us build and migrate into the new environment pretty seamlessly, with only a minor downtime while we swap out the old monolithic server with the new dedicated Graylog2 instance for that site. At a high level what we’ll need to do is
- Build the new servers.
- Add the new ElasticSearch data nodes to the cluster and adjust sharding configurations.
- Add the new Graylog2 Server instances to the cluster.
- Add the new Graylog2 Web instances to the cluster.
- Swap the existing Graylog2 Server instance.
- Remove the existing Graylog2 Server instance from the cluster.
- Remove the existing ElasticSearch data node from the cluster.
Over the course of the next few posts I’ll be documenting the process I took, all of the surprises that arose, and how I managed to beat each of them into submission.
Posts in this series
- Migrating Graylog Servers - Part 6 - Lessons Learned
- Migrating Graylog Servers - Part 5
- Migrating Graylog Servers - Part 4
- Migrating Graylog Servers - Part 3
- Migrating Graylog Servers - Part 2
- Migrating Graylog Servers